Databricks
Setup
Redash can connect to both Databricks clusters and SQL Endpoints. Consult the Databricks Documentation for how to obtain the Host, HTTP Path, and an Access Token for your endpoint.
Schema Browser
The Databricks query runner uses a custom built schema browser which allows you to switch between databases on the endpoint and see column types for each field.
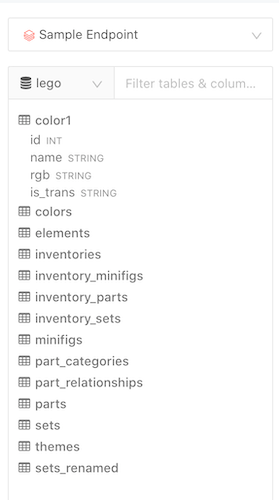
Unlike other query runners, the Databricks schema browser fetches table and column names on-demand as you navigate from one database to another. If you mostly use one database this will be fine.
But if you explore the schema across multiple databases you may experience delays as each database is fetched separately.
Schemas are cached for one hour. You may wish to schedule a hourly job to warm those caches.
You can do this with any REST API tool as follows:
curl --request GET \
--url http://<redash host>/api/databricks/databases/<data-source-id>/<database-name>/tables?refresh \
--header 'Authorization: Key <admin-api-key>' \Auto Limit
The Databricks query runner also includes a checkbox beneath the query editor which will append a LIMIT 1000 statement to your query automatically by default. This helps in case you accidentally run SELECT * FROM some large table with enough results to crash the front-end.
Multiple Statement Support
The Databricks query runner allows you to execute multiple statements terminated with a semicolon ; in one query window.
This is useful for setting session / cluster configuration variables prior to executing the query on your cluster.
set use_cached_result = False;
SELECT count(*) FROM some_db.some_table