Querying Existing Query Results
The Query Results Data Source (QRDS) lets you run queries against results from your other Data Sources. Use it to join data from multiple databases or perform post-processing. Redash uses an in-memory SQLite database to make this possible. As a result, queries against large result sets may fail if Redash runs out of memory.
Setup
You can enable Query Results under the Data Source tab of the settings menu. Setup is easy: just provide a name for the source.
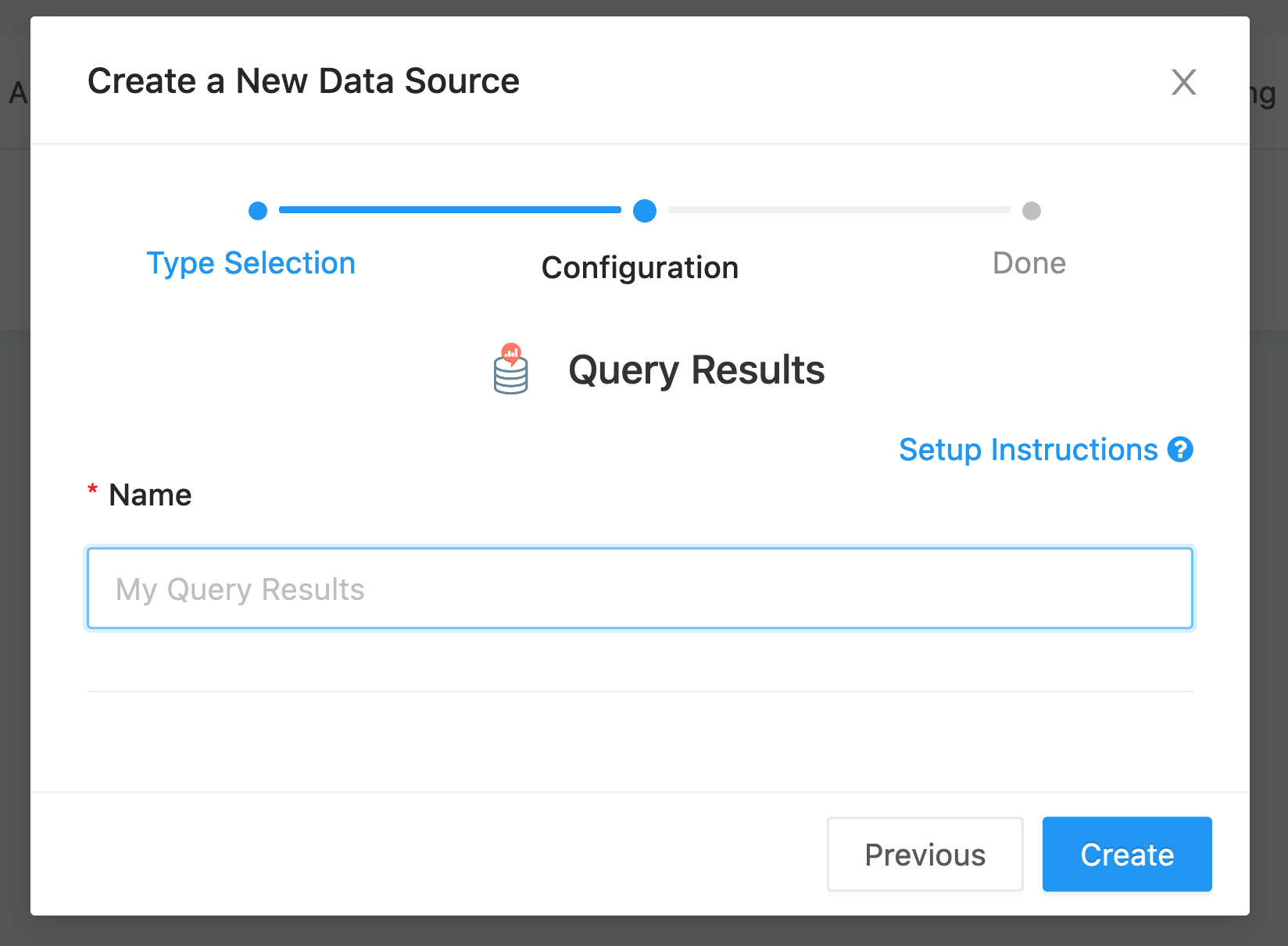
This is the name that will appear in the source dropdown on the left of the query editor. The data source is called Query Results in the below screenshot.
Most organizations only require one Query Results data source.
Querying
The QRDS accepts SQLite query syntax:
SELECT
a.name,
b.count
FROM query_123 AS a
JOIN query_456 AS b
ON a.id = b.idYour other queries are like “tables” to the QRDS. Each one is aliased as query_ followed by its query_id which you can see in the URL bar of your browser from the query editor. For example, a query at /queries/49588 has the alias query_49588.
query_49588 must appear on the same line as its associated FROM or JOIN keyword.
Cached Query Results
When you query the Query Results Data Source, Redash executes the underlying queries first. This guarantees recent results in case you schedule a QRDS query. You can speed up QRDS queries by using cached_query_ for your query aliases instead of query_. This tells Redash to use the cached results from the most recent execution of a given query. This improves performance by using older data. You can mix both syntaxes in the same query too:
SELECT
a.name,
b.count
FROM cached_query_123 AS a
JOIN query_456 AS b
ON a.id = b.idQuery Results Permissions
Access to the Query Results Data Source is governed by the groups it’s associated with like any other Data Source. But Redash will also check if a user has permission to execute queries on the Data Sources the original queries use.
As an example, a user with access to the QRDS cannot execute SELECT * FROM query_123 if query 123 uses a data source to which that user does not have access. They will see the most recently cached QRDS query result from the query screen in Redash. But they will not be able to execute the query again.
Using Query Parameters
You can now use query parameters with the Query Results Data Source.
Use the following syntax to reference a parameterized query:
param_query_<query_id>_{<URL ENCODED KEY=VALUE PARAMETER STRING>}
For example, suppose the original query (ID: 123) is:
SELECT
name
FROM users
WHERE id = {{id}}You can pass parameters in your Query Results query like this:
SELECT
a.name
FROM param_query_123_{id=1} AS a